NVIDIA NeMo フレームワーク

仕様
- 製品名: NVIDIA NeMo フレームワーク
- 影響を受けるプラットフォーム: Windows、Linux、macOS
- 影響を受けるバージョン: 24 より前のすべてのバージョン
- セキュリティの脆弱性: 脆弱性
- リスク評価基本スコア: 7.1 (CVSS v3.1)
製品使用説明書
セキュリティ更新プログラムのインストール:
システムを保護するには、次の手順に従ってください。
- GitHub の NeMo-Framework-Launcher リリース ページから最新リリースをダウンロードしてください。
- 詳細については、NVIDIA 製品セキュリティをご覧ください。
セキュリティアップデートの詳細:
このセキュリティアップデートは、コード実行やデータ漏洩につながる可能性のあるNVIDIA NeMoフレームワークの脆弱性に対処しています。ampエリング。
ソフトウェアの更新:
以前のブランチ リリースを使用している場合は、セキュリティの問題に対処するために、最新のブランチ リリースにアップグレードすることをお勧めします。
以上view
NVIDIA NeMoフレームワークは、スケーラブルでクラウドネイティブな生成AIフレームワークであり、 大規模言語モデル、マルチモーダル、そして 音声AI (例えば 自動音声認識 そして テキスト読み上げ)。これにより、ユーザーは既存のコードと事前トレーニング済みのモデル チェックポイントを活用して、新しい生成 AI モデルを効率的に作成、カスタマイズ、展開できるようになります。
セットアップ手順: NeMoフレームワークをインストールする
NeMoフレームワークは、大規模言語モデル(LLM)とマルチモーダルモデル(MM)の開発をエンドツーエンドでサポートします。オンプレミス、データセンター、またはお好みのクラウドプロバイダーで使用できる柔軟性を備えています。また、SLURMまたはKubernetes対応環境での実行もサポートしています。

データキュレーション
NeMoキュレーター [1] は、データマイニングと合成データ生成のためのモジュールスイートを含むPythonライブラリです。スケーラブルでGPU向けに最適化されているため、LLMの学習や微調整のための自然言語データのキュレーションに最適です。NeMo Curatorを使用すると、膨大な生データから高品質なテキストを効率的に抽出できます。 web データ ソース。
トレーニングとカスタマイズ
NeMoフレームワークは、効率的なトレーニングとカスタマイズのためのツールを提供します。 LLM(法学修士) マルチモーダルモデルにも対応しています。計算クラスタのセットアップ、データのダウンロード、モデルのハイパーパラメータのデフォルト設定が含まれており、新しいデータセットやモデルで学習する際に調整できます。事前学習に加えて、NeMoはLoRA、Ptuningなどの教師ありファインチューニング(SFT)とパラメータ効率の良いファインチューニング(PEFT)の両方の手法をサポートしています。
NeMo でトレーニングを開始するには、NeMo 2.0 API インターフェースを使用するか、NeMo Run を使用するかの XNUMX つのオプションがあります。
- NeMo Run を使用する場合(推奨): NeMo Runは、様々なコンピューティング環境における実験の設定、実行、管理を効率化するためのインターフェースを提供します。これには、ワークステーション上でのローカルジョブの起動、またはSLURM対応の大規模クラスターやクラウド環境のKubernetesでのジョブの起動が含まれます。
- NeMo Run による事前トレーニングと PEFT クイックスタート
- NeMo 2.0 API の使用: この方法は、小規模なモデルを扱うシンプルなセットアップ、あるいは独自のカスタムデータローダー、トレーニングループ、あるいはモデルレイヤーの変更を希望する場合に適しています。これにより、設定に対する柔軟性と制御性が向上し、プログラムによる設定の拡張やカスタマイズが容易になります。
-
トラNeMo 2.0 APIを使用したクイックスタート
-
NeMo 1.0 から NeMo 2.0 API への移行
-
アライメント
- NeMoアライナー [1] は、効率的なモデルアライメントのためのスケーラブルなツールキットです。このツールキットは、SteerLM、DPO、人間からのフィードバックによる強化学習(RLHF)など、最先端のモデルアライメントアルゴリズムをサポートしています。これらのアルゴリズムにより、ユーザーは言語モデルをより安全で無害かつ有用なものにアライメントできます。
- すべての NeMo-Aligner チェックポイントは NeMo エコシステムと相互互換性があり、さらなるカスタマイズと推論の展開が可能になります。
小規模な GPT-2B モデルでの RLHF の XNUMX つのフェーズすべてのステップバイステップのワークフロー:
- SFTトレーニング
- 報酬モデルのトレーニング
- PPOトレーニング
さらに、他のさまざまな新しいアライメント方法のサポートも示します。
- 個人情報保護方針: RLHF に比べて損失関数が単純な軽量アライメント アルゴリズムです。
- セルフプレイ 微調整(SPIN)
- ステアLM: 出力を制御できる条件付き SFT に基づく技術。
詳細については、ドキュメントをご覧ください。 アライメントドキュメント
マルチモーダルモデル
- NeMo フレームワークは、マルチモーダル言語モデル、ビジョン言語基盤、テキストから画像へのモデル、Neural Radiance Fields (NeRF) を使用した 2D 生成など、複数のカテゴリにわたって最先端のマルチモーダル モデルをトレーニングおよび展開するための最適化されたソフトウェアを提供します。
- 各カテゴリは、最先端のモデルを活用してテキスト、画像、3D モデルなどの幅広いデータ タイプを処理し、分野の特定のニーズと進歩に対応するように設計されています。
注記
NeMo 1.0からNeMo 2.0へマルチモーダルモデルのサポートを移行中です。移行期間中にこの領域について詳細を知りたい場合は、NeMo 24.07(以前のリリース)のドキュメントをご覧ください。
展開と推論
NeMo フレームワークは、さまざまな展開シナリオとパフォーマンスのニーズに対応して、LLM 推論のためのさまざまなパスを提供します。
NVIDIA NIMで導入
- NeMoフレームワークは、NVIDIA NIMを介してエンタープライズレベルのモデルデプロイメントツールとシームレスに統合されます。この統合はNVIDIA TensorRT-LLMを活用しており、最適化されたスケーラブルな推論を実現します。
- NIMの詳細については、NVIDIAの webサイト。
TensorRT-LLM または vLLM を使用してデプロイする
- NeMo フレームワークは、モデルを 2 つの推論最適化ライブラリ (TensorRT-LLM と vLLM) にエクスポートし、エクスポートしたモデルを NVIDIA Triton 推論サーバーで展開するためのスクリプトと API を提供します。
- パフォーマンスの最適化が求められるシナリオでは、NeMoモデルはTensorRT-LLMを活用できます。TensorRT-LLMは、NVIDIA GPU上でLLM推論を高速化および最適化するための専用ライブラリです。このプロセスでは、nemo.exportモジュールを使用して、NeMoモデルをTensorRT-LLMと互換性のある形式に変換します。
- LLMの導入完了view
- NIM で NeMo 大規模言語モデルを展開する
- TensorRT-LLM を使用した NeMo 大規模言語モデルのデプロイ
- vLLM で NeMo 大規模言語モデルをデプロイする
対応モデル
大規模言語モデル
| 大規模言語モデル | 事前トレーニングとSFT | PEFT | アライメント | FP8トレーニングの収束 | TRT/TRTLLM | ハグフェイスへの変換とハグフェイスからの変換 | 評価 |
|---|---|---|---|---|---|---|---|
| ラマ3 8B/70B、ラマ3.1 405B | はい | はい | x | はい(部分的に確認済み) | はい | 両方 | はい |
| ミクストラル 8x7B/8x22B | はい | はい | x | はい(未確認) | はい | 両方 | はい |
| ネモトロン 3 8B | はい | x | x | はい(未確認) | x | 両方 | はい |
| ネモトロン 4 340B | はい | x | x | はい(未確認) | x | 両方 | はい |
| 白川2 7B | はい | はい | x | はい(未確認) | x | 両方 | はい |
| チャットGLM3 6B | はい | はい | x | はい(未確認) | x | 両方 | はい |
| ジェマ 2B/7B | はい | はい | x | はい(未確認) | はい | 両方 | はい |
| ジェマ2 2B/9B/27B | はい | はい | x | はい(未確認) | x | 両方 | はい |
| Mamba2 130M/370M/780M/1.3B/2.7B/8B/ Hybrid-8B | はい | はい | x | はい(未確認) | x | x | はい |
| Phi3 ミニ 4K | x | はい | x | はい(未確認) | x | x | x |
| Qwen2 0.5B/1.5B/7B/72B | はい | はい | x | はい(未確認) | はい | 両方 | はい |
| スターコーダー15B | はい | はい | x | はい(未確認) | はい | 両方 | はい |
| スターコーダー2 3B/7B/15B | はい | はい | x | はい(未確認) | はい | 両方 | はい |
| BERT 110M/340M | はい | はい | x | はい(未確認) | x | 両方 | x |
| T5 220M/3B/11B | はい | はい | x | x | x | x | x |
視覚言語モデル
| 視覚言語モデル | 事前トレーニングとSFT | PEFT | アライメント | FP8トレーニングの収束 | TRT/TRTLLM | ハグフェイスへの変換とハグフェイスからの変換 | 評価 |
|---|---|---|---|---|---|---|---|
| ネヴァ(LLaVA 1.5) | はい | はい | x | はい(未確認) | x | から | x |
| ラマ 3.2 ビジョン 11B/90B | はい | はい | x | はい(未確認) | x | から | x |
| LLaVA ネクスト (LLaVA 1.6) | はい | はい | x | はい(未確認) | x | から | x |
埋め込みモデル
| 言語モデルの埋め込み | 事前トレーニングとSFT | PEFT | アライメント | FP8トレーニングの収束 | TRT/TRTLLM | ハグフェイスへの変換とハグフェイスからの変換 | 評価 |
|---|---|---|---|---|---|---|---|
| SBERT 340M | はい | x | x | はい(未確認) | x | 両方 | x |
| ラマ 3.2 埋め込み 1B | はい | x | x | はい(未確認) | x | 両方 | x |
世界基盤モデル
| 世界基盤モデル | 研修後 | 加速推論 |
|---|---|---|
| コスモス-1.0-拡散-テキスト2ワールド-7B | はい | はい |
| コスモス-1.0-拡散-テキスト2ワールド-14B | はい | はい |
| コスモス-1.0-拡散-Video2World-7B | 近日公開 | 近日公開 |
| コスモス-1.0-拡散-Video2World-14B | 近日公開 | 近日公開 |
| コスモス-1.0-自己回帰-4B | はい | はい |
| コスモス-1.0-自己回帰-ビデオ2ワールド-5B | 近日公開 | 近日公開 |
| コスモス-1.0-自己回帰-12B | はい | はい |
| コスモス-1.0-自己回帰-ビデオ2ワールド-13B | 近日公開 | 近日公開 |
注記
NeMoは拡散アーキテクチャと自己回帰アーキテクチャの両方の事前学習もサポートしています。 text2world 基礎モデル。
音声AI
会話型AIモデルの開発は、特定のドメインにおけるモデルの定義、構築、トレーニングを含む複雑なプロセスです。このプロセスでは通常、高い精度を達成するには複数回の反復処理が必要です。高い精度を達成するには、様々なタスクやドメイン固有のデータに基づいた微調整、トレーニングパフォーマンスの確保、そして推論展開に向けたモデルの準備など、複数の反復処理が必要となることも少なくありません。
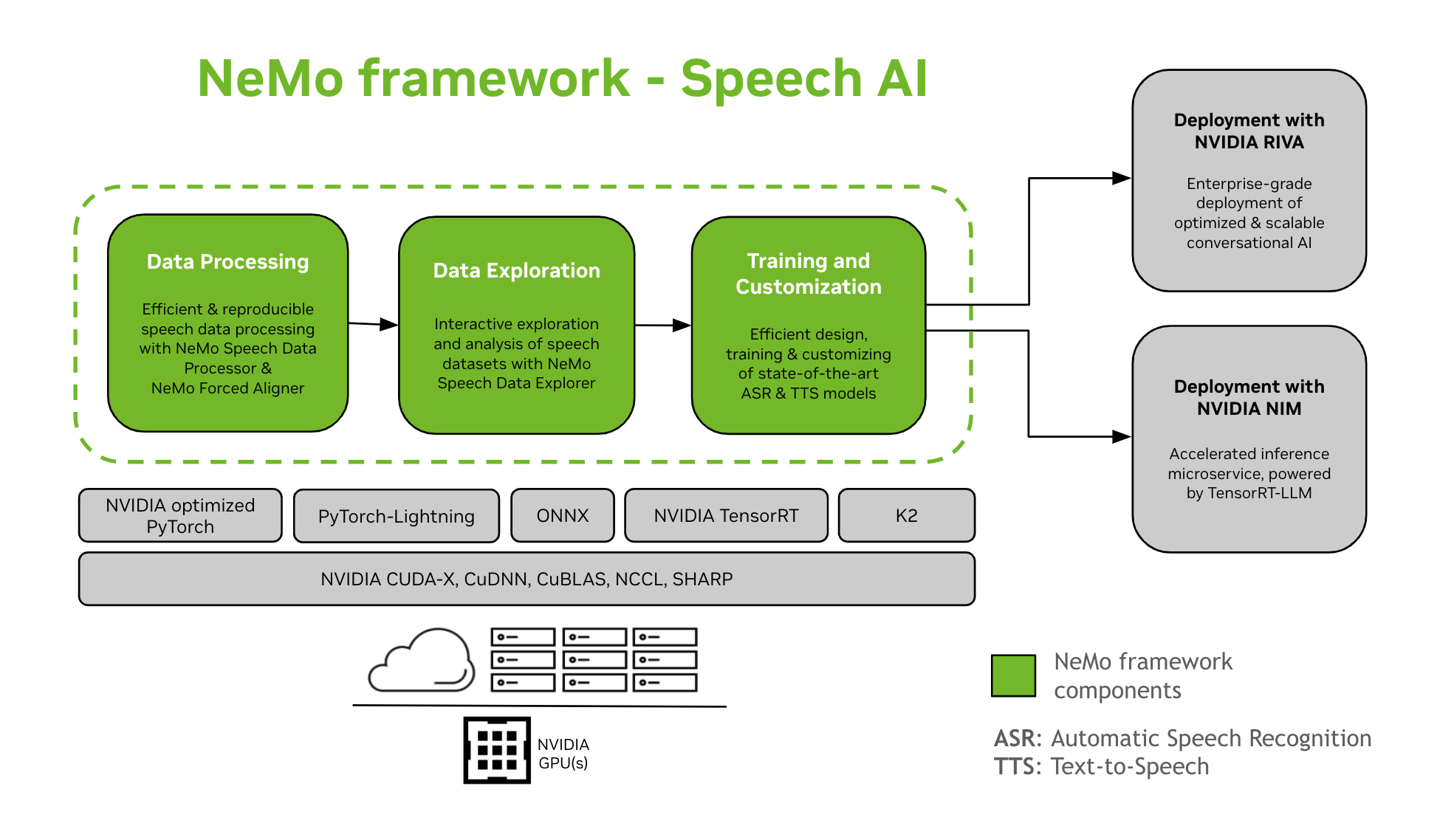
NeMoフレームワークは、音声AIモデルのトレーニングとカスタマイズをサポートします。これには、自動音声認識(ASR)や音声合成(TTS)といったタスクが含まれます。NVIDIA Rivaとの連携により、エンタープライズレベルの本番環境へのスムーズな移行を実現します。開発者や研究者を支援するため、NeMoフレームワークには、最先端の事前トレーニング済みチェックポイント、再現性の高い音声データ処理ツール、音声データセットのインタラクティブな探索・分析機能が搭載されています。NeMoフレームワーク for Speech AIのコンポーネントは次のとおりです。
トレーニングとカスタマイズ
NeMoフレームワークには、音声モデルのトレーニングとカスタマイズに必要なものがすべて含まれています(自動翻訳, 音声分類, 話者認識, 話者ダイアライゼーション、 そして 翻訳) を再現可能な方法で実行します。
SOTA事前学習済みモデル
- NeMoフレームワークは、最先端のレシピと、いくつかの事前学習済みチェックポイントを提供します。 自動翻訳 そして 翻訳 モデルと、それらをロードする方法の説明も含まれています。
- スピーチツール
- NeMo フレームワークは、次のような ASR および TTS モデルの開発に役立つ一連のツールを提供します。
- NeMo 強制アライナー (NFA) トークン、単語、セグメントレベルのタイムスタンプを生成するampNeMo の CTC ベースの自動音声認識モデルを使用して、オーディオ内の音声を分析します。
- 音声データプロセッサ(SDP)音声データ処理を簡素化するツールキット。データ処理操作を構成内で表現できます。 file定型コードを最小限に抑え、再現性と共有性を実現します。
- 音声データエクスプローラー(SDE)、ダッシュベースの web 音声データセットのインタラクティブな探索と分析のためのアプリケーション。
- データセット作成ツール 長い音声を揃える機能を提供する fileを対応するトランスクリプトと照合し、自動音声認識 (ASR) モデルのトレーニングに適した短いフラグメントに分割します。
- 比較ツール ASR モデルでは、単語の精度と発話レベルでさまざまな ASR モデルの予測を比較できます。
- ASR評価者 ASR モデルや音声アクティビティ検出などのその他の機能のパフォーマンスを評価するため。
- テキスト正規化ツール テキストを書き言葉から話し言葉へ、またはその逆へ変換します(例:「31st」と「thirty first」)。
- 展開への道
- NeMo フレームワークを使用してトレーニングまたはカスタマイズされた NeMo モデルは、NVIDIA Riva を使用して最適化およびデプロイできます。Riva は、プッシュボタンによるデプロイ手順を自動化するために特別に設計されたコンテナーと Helm チャートを提供します。
その他のリソース
- ネモ: NeMoフレームワークのメインリポジトリ
- ネモ–走る: 機械学習実験を構成、起動、管理するためのツール。
- NeMo-Aligner: 効率的なモデル調整のためのスケーラブルなツールキット
- NeMoキュレーター: LLM 向けのスケーラブルなデータ前処理およびキュレーション ツールキット
NeMo コミュニティに参加し、質問したり、サポートを受けたり、バグを報告したりできます。
- NeMoの議論
- NeMoの問題
プログラミング言語とフレームワーク
- パイソン: NeMo Frameworkを使用するためのメインインターフェース
- ピトーチNeMoフレームワークはPyTorch上に構築されています
ライセンス
- NeMo GithubリポジトリはApache 2.0ライセンスの下でライセンスされています
- NeMo フレームワークは、NVIDIA AI 製品契約に基づいてライセンスされています。コンテナをプルして使用することにより、このライセンスの条件に同意したことになります。
- NeMo フレームワーク コンテナーには、Meta Llama3 コミュニティ ライセンス契約に準拠する Llama マテリアルが含まれています。
脚注
現在、マルチモーダル モデルに対する NeMo Curator と NeMo Aligner のサポートは進行中であり、まもなく利用可能になる予定です。
よくある質問
Q: システムが脆弱性の影響を受けているかどうかを確認するにはどうすればよいですか?
A: インストールされているNVIDIA NeMo Frameworkのバージョンを確認することで、システムが影響を受けているかどうかを確認できます。バージョン24未満の場合、システムは脆弱である可能性があります。
Q: セキュリティ問題 CVE-2025-23360 を報告したのは誰ですか?
A: このセキュリティ問題は、JFrog SecurityのOr Peles氏によって報告されました。NVIDIAは、同氏の貢献に感謝いたします。
Q: 今後のセキュリティ情報の通知を受け取るにはどうすればよいですか?
A: NVIDIA 製品セキュリティ ページにアクセスして、セキュリティ速報の通知を購読し、製品のセキュリティ更新に関する最新情報を入手してください。
ドキュメント / リソース
 |
NVIDIA NeMo フレームワーク [pdf] ユーザーガイド NeMo フレームワーク、NeMo、フレームワーク |